- Sun 25 August 2019
- datascience
- #multiclass classification, #XGBoost
About Dataset¶
Taken from data description: "In this dataset, you are provided over a hundred variables describing attributes of life insurance applicants. The task is to predict the "Response" variable for each Id in the test set. "Response" is an ordinal measure of risk that has 8 levels."
Things to note:
- The problem is an ordinal (ordered) multiclass classification problem
- The performance is measured by a submitted test set on Kaggle using a quadratic weighted kappa. This is just a measure of agreement between two classes.
- The dataset does not say the names of the 8 classes, so I dig deeper online and find the likely classifications that 0-8 corresponds to.
Variables¶
- Id | A unique identifier associated with an application.
- Product_Info_1-7 | A set of normalized variables relating to the product applied for
- Ins_Age | Normalized age of applicant
- Ht | Normalized height of applicant
- Wt | Normalized weight of applicant
- BMI | Normalized BMI of applicant
- Employment_Info_1-6 | A set of normalized variables relating to the employment history of the applicant.
- InsuredInfo_1-6 | A set of normalized variables providing information about the applicant.
- Insurance_History_1-9 | A set of normalized variables relating to the insurance history of the applicant.
- Family_Hist_1-5 | A set of normalized variables relating to the family history of the applicant.
- Medical_History_1-41 | A set of normalized variables relating to the medical history of the applicant.
- Medical_Keyword_1-48 | A set of dummy variables relating to the presence of/absence of a medical keyword being associated with the application.
- Response | This is the target variable, an ordinal variable relating to the final decision associated with an application
Imports¶
#exploration libraries
import numpy as np
import pandas as pd
import seaborn as sns
sns.set_style('darkgrid')
import matplotlib.pyplot as plt
from collections import Counter
from scipy import stats
from scipy.stats import norm, skew
%matplotlib inline
#modeling libraries
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.linear_model import RidgeClassifierCV
import xgboost as xgb
from xgboost import XGBClassifier
from sklearn.ensemble import RandomForestClassifier
from xgboost import plot_importance
from sklearn.metrics import classification_report, accuracy_score, confusion_matrix
from scipy.optimize import fmin_powell
from ml_metrics import quadratic_weighted_kappa
import warnings
warnings.filterwarnings("ignore")
train = pd.read_csv('train.csv')
Data Exploration¶
train.head()
train.info()
train.describe()
plt.figure(figsize=(14,6))
plt.title('Distribution of Risk Classifications')
sns.countplot(train['Response'])

#count and percentages of each class
print('counts\n' + str(train['Response'].value_counts())+\
'\n\npercentages\n'+ str(train['Response'].value_counts()/len(train)))
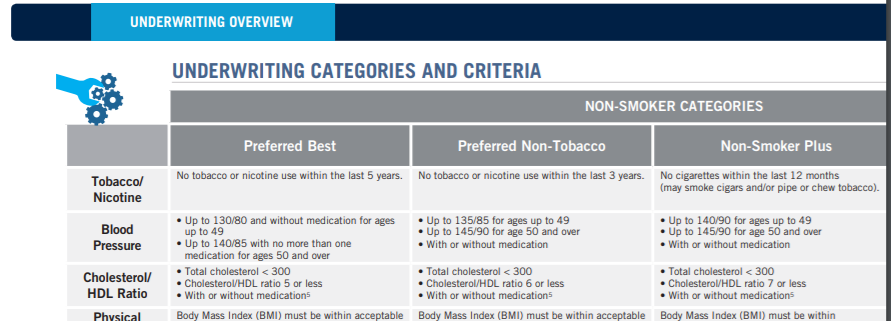
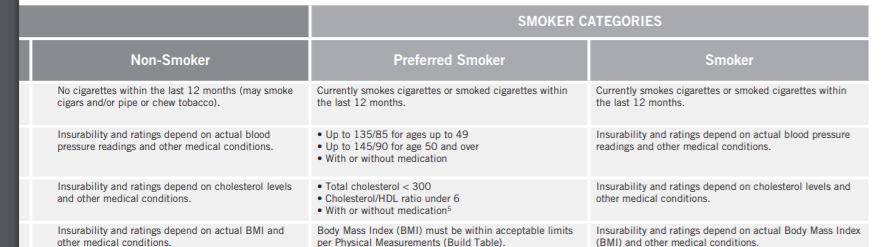
I did some digging on Prudential's underwriting and found their health classes are listed as follows: Preferred best, Preferred non-tobacco, non-smoker plus, non-smoker, preferred smoker, smoker, and substandard table scores. It would make sense that the two smoking categories are 3 and 4 since these are the least populated classifications. I will test this theory later in my analysis. Here are the underwriting guidelines:
#correlation matrix
plt.figure(figsize=(12,10))
plt.title('Heatmap of Correlations between all Variables')
sns.heatmap(train.corr(), square=True, cmap='coolwarm')

A few variables seem to have multicollinearity, but not enough to warrant more investigation or correction. A tiny percent of variables is unlikely to cause any performance issues for the model.
plt.figure(figsize=(12,10))
plt.title('Heatmap of 10 Highest Correlations with Response')
#selects 10 columns with highest correlation with 'SalePrice'
cols = abs(train.corr()).nlargest(10, 'Response')['Response'].index
#creates correlation matrix
#transpose values due to mix of quantitative and categorical data
cm = np.corrcoef(train[cols].values.T)
sns.heatmap(cm, square=True, annot=True, fmt='.2f',
yticklabels=cols.values, xticklabels=cols.values, cmap='coolwarm')

BMI and weight columns are the most predictive of risk classification followed by Medical_History columns
#Set up the matplotlib figure
f, axes = plt.subplots(2, 2, figsize=(16, 8), sharex=True)
ax1 = sns.boxplot(x='Response',y='Wt',data=train,ax=axes[0,0])
ax1.set_title('Weight')
ax2 = sns.boxplot(x='Response',y='BMI',data=train,ax=axes[0,1])
ax2.set_title('BMI')
ax3 = sns.boxplot(x='Response',y='Ht',data=train,ax=axes[1,0])
ax3.set_title('Height')
ax4 = sns.boxplot(x='Response',y='Ins_Age',data=train,ax=axes[1,1])
ax4.set_title('Insurance Age')

The data does not look ordered at first glance. It seems that 1 and 2 are most likely the highest risk classes, and 3 and 4 are smoking classes. The most likely explanation is that 1 is the highest risk and 8 is the lowest. This makes sense due to the dips in popularity at 3 and 4 indicating smoking classes which aligns with Prudential's underwriting classes.
Deanonymized Prudential Classifications (most likely)¶
- Substandard Smoker
- Substandard Non-smoker
- Smoker
- Preferred Smoker
- Non-smoker
- Non-smoker Plus
- Preferred Non-tobacco
- Preferred Best
#Set up the matplotlib figure
f, axes = plt.subplots(1, 2, figsize=(16, 6), sharex=True)
ax1 = sns.countplot(x='Response',hue='Medical_History_23',data=train,ax=axes[0])
ax2 = sns.countplot(x='Response',hue='Medical_History_4',data=train,ax=axes[1])

#the continuous columns given on the data description page
CONTINUOUS_COLUMNS = ["Product_Info_4", "Ins_Age", "Ht", "Wt", "BMI",
"Employment_Info_1", "Employment_Info_4", "Employment_Info_6",
"Insurance_History_5", "Family_Hist_2", "Family_Hist_3", "Family_Hist_4", "Family_Hist_5"]
continuous_data = train[CONTINUOUS_COLUMNS]
#display continuous data
def plot_histgrams(data):
ncols = len(data.columns)
fig = plt.figure(figsize=(5 * 5, 5 * (ncols // 5 + 1)))
for i, col in enumerate(data.columns):
X = data[col].dropna()
plt.subplot(ncols // 5 + 1, 5, i + 1)
plt.hist(X, bins=20, alpha=0.5, \
edgecolor="black", linewidth=2.0)
plt.xlabel(col, fontsize=18)
plt.ylabel("frequency", fontsize=18)
fig.tight_layout()
plt.show()
plot_histgrams(continuous_data)

The data description claims that the data is already normalized, and these plots look normal enough for modeling.
CATEGORICAL_COLUMNS = ["Product_Info_1", "Product_Info_2", "Product_Info_3", "Product_Info_5", "Product_Info_6",\
"Product_Info_7", "Employment_Info_2", "Employment_Info_3", "Employment_Info_5", "InsuredInfo_1",\
"InsuredInfo_2", "InsuredInfo_3", "InsuredInfo_4", "InsuredInfo_5", "InsuredInfo_6", "InsuredInfo_7",\
"Insurance_History_1", "Insurance_History_2", "Insurance_History_3", "Insurance_History_4", "Insurance_History_7",\
"Insurance_History_8", "Insurance_History_9", "Family_Hist_1", "Medical_History_3",\
"Medical_History_4", "Medical_History_5", "Medical_History_6", "Medical_History_7", "Medical_History_8",\
"Medical_History_9", "Medical_History_11", "Medical_History_12", "Medical_History_13", "Medical_History_14",\
"Medical_History_16", "Medical_History_17", "Medical_History_18", "Medical_History_19", "Medical_History_20",\
"Medical_History_21", "Medical_History_22", "Medical_History_23", "Medical_History_25", "Medical_History_26",\
"Medical_History_27", "Medical_History_28", "Medical_History_29", "Medical_History_30", "Medical_History_31",\
"Medical_History_33", "Medical_History_34", "Medical_History_35", "Medical_History_36", "Medical_History_37",\
"Medical_History_38", "Medical_History_39", "Medical_History_40", "Medical_History_41"]
categorical_data = train[CATEGORICAL_COLUMNS]
# display categorical data
def plot_categoricals(data):
ncols = len(data.columns)
fig = plt.figure(figsize=(5 * 5, 5 * (ncols // 5 + 1)))
for i, col in enumerate(data.columns):
#counter dictionary for frequency of each unique value in column
cnt = Counter(data[col])
keys = list(cnt.keys())
vals = list(cnt.values())
plt.subplot(ncols // 5 + 1, 5, i + 1)
plt.bar(range(len(keys)), vals, align="center")
plt.xticks(range(len(keys)), keys)
plt.xlabel(col, fontsize=18)
plt.ylabel("frequency", fontsize=18)
fig.tight_layout()
plt.show()
plot_categoricals(categorical_data)

Data Cleaning¶
test = pd.read_csv('test.csv')
#concatenate train and test for feature engineering
all_data = pd.concat((train, test)).reset_index(drop=True)
all_data.head()
Feature Engineering¶
all_data['Product_Info_2'].head()
I was only having trouble plotting Product_Info_2, so looking closer it has a system of a letter followed by a number for each product. I am going to assume that the letter is a certain category and I'm not sure what the number is, so I'll make features for all of these to feed to the model just in case:
#extract character fron Product_Info_2
all_data['Product_Info_2_char'] = all_data.Product_Info_2.str[0]
#extract number from Product_Info_2
all_data['Product_Info_2_num'] = all_data.Product_Info_2.str[1]
#use factorize to identify distinct values (non-ordinal)
all_data['Product_Info_2'] = pd.factorize(all_data['Product_Info_2'])[0]
all_data['Product_Info_2_char'] = pd.factorize(all_data['Product_Info_2_char'])[0]
all_data['Product_Info_2_num'] = pd.factorize(all_data['Product_Info_2_num'])[0]
#multiply BMI by age
all_data['BMI_Age'] = all_data['BMI'] * all_data['Ins_Age']
#count total medical keywords from 48 columns
med_keyword_columns = all_data.columns[all_data.columns.str.startswith('Medical_Keyword_')]
all_data['Med_Keywords_Total'] = all_data[med_keyword_columns].sum(axis=1)
#count missing values
all_data['countna'] = all_data.apply(lambda x: sum(x.isnull()),1)
# split train and test
train = all_data[pd.notna(all_data['Response'])]
test = all_data[pd.isna(all_data['Response'])]
Missing Values¶
missing = all_data.isnull().sum().sort_values(ascending=False)
pct = (all_data.isnull().sum()/all_data.isnull().count()*100).sort_values(ascending=False)
#creates dataframe with missing and pct missing
miss_data = pd.concat([missing, pct], axis=1, keys=['Missing','Percent'])
#shows columns with missing values
miss_data[miss_data['Missing']>0]
#drop columns with >90% data missing
all_data.drop(['Medical_History_10','Medical_History_24','Medical_History_32'],
axis=1,inplace=True)
Evaluate non-dropped columns with <15% missing info:
all_data['Employment_Info_4'].describe()
plt.figure(figsize=(12,4))
plt.title('Distribution of Employment_Info_4')
sns.distplot(all_data[all_data['Employment_Info_4']>0]['Employment_Info_4'])

all_data['Employment_Info_1'].describe()
plt.figure(figsize=(12,4))
plt.title('Distribution of Employment_Info_1')
sns.distplot(all_data[all_data['Employment_Info_1']>=0]['Employment_Info_1'])

#impute missing values with median
for col in ('Employment_Info_1','Employment_Info_4'):
all_data[col] = all_data[col].fillna(all_data[col].median())
#use -1 as placeholder for remaining missing values
all_data.fillna(-1, inplace=True)
#split train and test
train = all_data[all_data['Response']>0]
test = all_data[all_data['Response']<1]
Modeling¶
Without Optimization on Validation Set¶
I chose 4 models: XGBoost, ridge classifier, One vs. Rest logistic regression, and random forest because these are popular methods for solving multiclass classification problems. I then benchmark these basic models on a train/validation split to pick a model to optimize.
y = train['Response']
X = train.drop(['Response','Id'],axis=1)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
xgbmodel = XGBClassifier(objective='reg:linear')
#xgbmodel = XGBClassifier(objective='multi:softmax')
xgbmodel.fit(X_train,y_train)
xgb_pred = xgbmodel.predict(X_test)
print(accuracy_score(y_test,xgb_pred))
rcmodel = RidgeClassifierCV()
rcmodel.fit(X_train,y_train)
rc_pred = rcmodel.predict(X_test)
print(accuracy_score(y_test,rc_pred))
logmodel = LogisticRegression(multi_class='ovr')
logmodel.fit(X_train,y_train)
log_pred = logmodel.predict(X_test)
print(accuracy_score(y_test,log_pred))
rfmodel = RandomForestClassifier()
rfmodel.fit(X_train,y_train)
rf_pred = rfmodel.predict(X_test)
print(accuracy_score(y_test,rf_pred))
print('Accuracies without optimization\n-------------------------------')
print('XGBoost: ' + str("{0:.3f}".format(accuracy_score(y_test,xgb_pred))))
print('Logistic Regression: ' + str("{0:.3f}".format(accuracy_score(y_test,log_pred))))
print('Random Forest: ' + str("{0:.3f}".format(accuracy_score(y_test,rf_pred))))
print('Ridge Classifier: ' + str("{0:.3f}".format(accuracy_score(y_test,rc_pred))))
Model Optimization¶
XGBoost performed the best by far without optimization compared to other multiclass classification techniques. I am using a linear XGBoost method due to the data being ordinal, and giving similar performance to an XGBClassifier. This gives me the advantage of setting offsets (essentially cutoffs for each class) to optimize classification compared to a classification method that treats each class as discrete.
def eval_wrapper(yhat, y):
"""
This method takes y predictions and actual y as input and returns a
quadratic weighted kappa score (metric used for competition, similar to accuracy)
"""
y = np.array(y) #
y = y.astype(int) #fix response datatype
yhat = np.array(yhat)
yhat = np.clip(np.round(yhat), np.min(y), np.max(y)).astype(int)
return quadratic_weighted_kappa(yhat, y)
def score_offset(data, bin_offset, sv):
"""
This method assigns a score to a specific offset to be used for optimization.
I use this function to assign many offset scores and uses the fmin_powell function
to select the best offset for a given class
"""
# data has format of prediction=0, offset prediction=1, actual label=2
data[1, data[0].astype(int)==sv] = data[0, data[0].astype(int)==sv] + bin_offset
score = eval_wrapper(data[1], data[2])
return score
def apply_offsets(data, offsets):
"""
This method applies the chosen offset from fmin_powell function to each of the 8 classes
"""
for j in range(8):
data[1, data[0].astype(int)==j] = data[0, data[0].astype(int)==j] + offsets[j]
return data
# convert data to a dense matrix for faster XGBoost processing times
xgtrain = xgb.DMatrix(train.drop(['Id','Response'],axis=1), train['Response'].values, missing=-1)
xgtest = xgb.DMatrix(test.drop(['Id','Response'],axis=1), label=test['Response'].values, missing=-1)
#parameters taken from high-performing Kaggle kernel
param_lst = [('objective', 'reg:linear'),
('eta', 0.05),
('min_child_weight', 240),
('subsample', 0.9),
('colsample_bytree', 0.67),
('silent', 1),
('max_depth', 6)]
xgbmodel = xgb.train(param_lst, xgtrain, num_boost_round=800)
xgb.plot_importance(xgbmodel)

#get predictions
train_preds = xgbmodel.predict(xgtrain, ntree_limit=xgbmodel.best_iteration)
test_preds = xgbmodel.predict(xgtest, ntree_limit=xgbmodel.best_iteration)
print('Train score is:', eval_wrapper(train_preds, train['Response']))
#train offsets
offsets = np.array([0.1, -1, -2, -1, -0.8, 0.02, 0.8, 1])
offset_preds = np.vstack((train_preds, train_preds, train['Response'].values))
offset_preds = apply_offsets(offset_preds, offsets)
opt_order = [6,4,5,3]
for j in opt_order:
train_offset = lambda x: -score_offset(offset_preds, x, j) * 100
offsets[j] = fmin_powell(train_offset, offsets[j], disp=False)
print('Offset Train score is:', eval_wrapper(offset_preds[1], train['Response']))
#apply offsets to test data
data = np.vstack((test_preds, test_preds, test['Response'].values))
data = apply_offsets(data, offsets)
xgb_pred = np.round(np.clip(data[1], 1, 8)).astype(int)
#create dataframe for Kaggle Submission
df = pd.DataFrame({'Id' : test['Id'], 'Response' : xgb_pred})
df.Response = df.Response.astype('int32')
df.to_csv('xgb_submit_2.csv', index=False)
#Placed 809 out of 2619 with score of 0.66746
#For reference, first place scored 0.67938
df.head()
from IPython.display import Image
Image(filename='LI_results.png')
