- Mon 07 January 2019
- datascience
- #storytelling, #selection bias
During WWII, a statistician named Abraham Wald was asked to help the US decide where to add armor to their bombers. Researchers from the Center for Naval Analyses conducted a study and recommended adding armor to where the most damage occurred, but Wald paradoxically recommended adding armor where there was no damage! Wald realized that his data only came from bombers that survived; those that were shot down over enemy territory were not part of the sample. Wald assumed an equal distribution of holes in the plane, so undamaged areas of the surviving planes showed where the lost planes must have been hit as shown in the figure below:
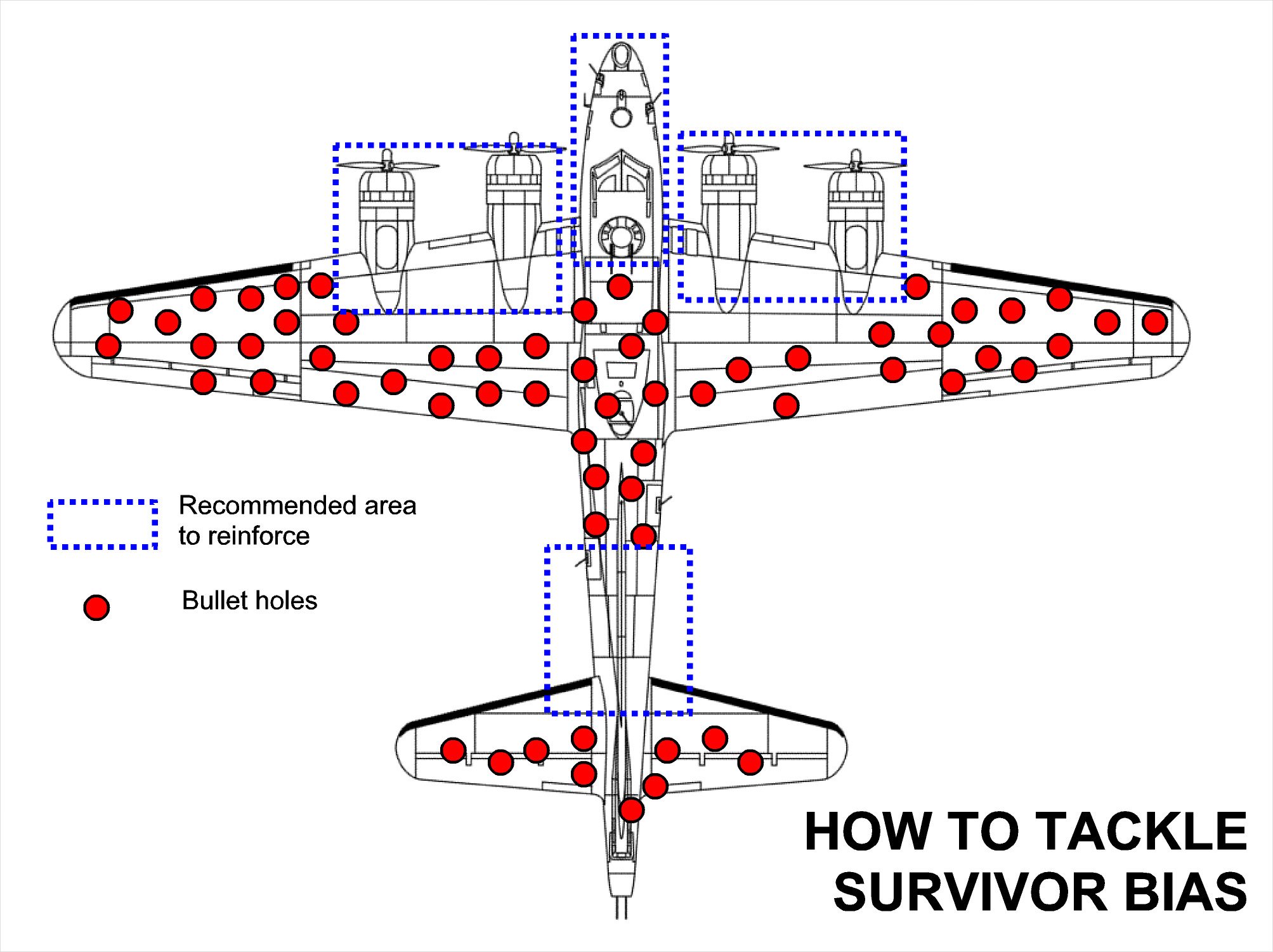
Wald had realized that his sample contained selection bias, and made a decision accordingly which potentially saved many lives.
So what is selection bias and why does it happen?¶
Selection bias is when the sample data that is gathered and prepared for modeling has characteristics that are not representative of the true, future population of cases the model will see. Basically, selection bias occurs when a subset of the data are excluded from the analysis.
Selection bias occurs because data scientists often do not get to decide where data samples come from or how they are conducted, which means that there is no certainty that all subsets of a sample are covered or if these subsets are proportional to the actual population. Even when data are carefully constructed in controlled statistical experiments, selection bias can still occur because there is a practical limit to what can be known about a population and put into a dataset.
So why does selection bias matter to data science and how can this problem be reduced?¶
Creating samples is a necessary part of building predictive models, but data scientists must be careful to build their data sets without bias. Predictive algorithms are already being used by courts, bank, and other institutions to make decisions about our lives, so the stakes for preventing selection bias involves the livelihood of citizens data science means to help. The problem is that to a modeling algorithm, the sample given is the only "world" it sees and will make decisions with or without bias. If data scientists end up using a biased sample, their conclusions can be inaccurate and even harmful to a society increasingly reliant on predictive algorithms.
In order to reduce the harmful consequences of selection bias, I propose three effective and practical strategies:
- Built datasets must closes represent the population of interest. A way to do this is through a stratified sample, where each important input category in the data is sampled separately and then those subsets are joined according to their correct proportions.
- The sampling strategy of the data should be documented so that limitations of its collection can be communicated and selection bias can be looked for once the model is built.
- Predictive models should be regularly reviewed after being deployed. A natural change in the population over time could decrease performance and increase bias in the model.
Through these methods, selection bias can be reduced so that society can expect to benefit, not be harmed, from advances in data science.